This article might be more meaningful to product leaders working in organizations that have implemented a structured process of innovation (NPD) in some format – like a Stage/Gate or a process that captures ideas from employees and channels them through a structured process for evaluation/monitoring.
What is fuzzy front-end?
Per PDMA, it is the messy “getting started” period of product development that precedes the more formal product development process. It consists of three tasks: strategic planning, concept generation, and, especially, pre-technical evaluation. Activities are often chaotic, unpredictable, and unstructured. In comparison, the subsequent new product development process is typically structured, predictable, and formal, with prescribed sets of activities, questions to be answered, and decisions to be made.
Typically, in most of the organizations, a fuzzy front-end stage is characterized by opportunity identification, idea generation and evaluation. And, a cross-functional team of experts that form an NPD group spend hours to review the assorted list of the submitted ideas and shortlist a few that seem to have potential for commercialization. This manual effort could be automated using a simple AI based solution – IF there exists a good amount of data on ideas that were captured and reviewed earlier.
How AI can be used in the fuzzy front-end stage?
AI needs large amounts of data to train and deploy a machine learning model that could identify patterns and generate predictions. But, given the likelihood of limited amounts of data captured by organizations as part of their innovation or New Product Development process (including the fuzzy front-end stage), does it make sense to use AI? If it does, how can it be used?
Or, putting the question the other way – Can we build a machine learning model that finds patterns or similarities in the ideas that are being generated in 100s, if not 1000s, every year from employees in organizations? And, also predict the success rate of commercializing these ideas?
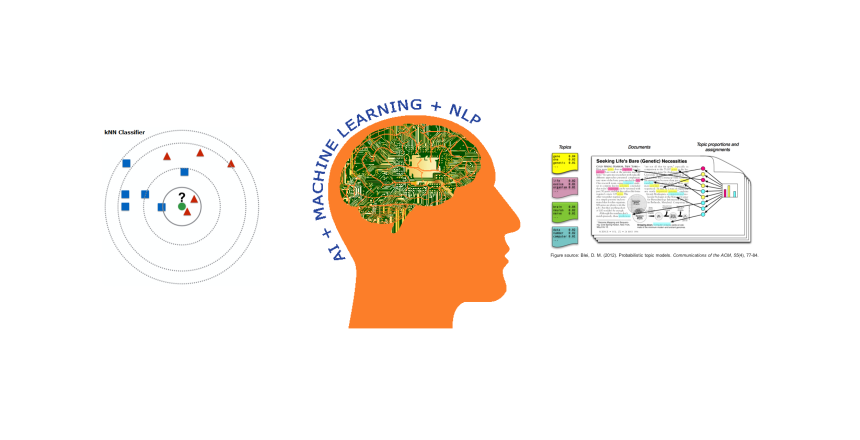
The above question could be addressed with an easy to implement AI based solution – using a kNN classifier that requires manual annotation (Supervised Learning).
If the organization currently has implemented an ideas portal that nets the ideas from employees across the business divisions and departments, and say, has several fields that an ideating employee has to fill-up to submit and later for evaluation, then, it is possible to build a kNN classifier and integrate it into the portal.
First and foremost, the data that was captured till date and going to be captured in the future, needs to be cleaned-up and organized into a standard format that will be used for our classification.
For e.g., take a simple screen in the ideas portal that captures Employee ID, Department, Division, Idea, How the idea was conceived, Source of the idea, Summary and/or Description of the idea, Rough sketch of the idea, Projected benefits, Potential competitors, Product Features etc..
To the above input fields in the screen, add a new column, say, Profitability index, which will be used as a measurement metric and is the projected output of our classifier.
Profitability index itself could be arrived from several metrics like customer acceptance, profit goals, performance or competitive advantage etc.., each one of which is used for measuring success based on the organization’s NPD/ Innovation strategy.
For the existing data that was captured till date, update this output field with values based on the previous reviews done by the cross-functional team of experts from respective domains. This data will be used for training the kNN classifier.
Wherever possible, the input fields should be organized by mapping them to closed questions and providing them as a set of options (like value labels that are used to capture data for Statistical analysis in tools like SPSS).
For the open questions like “How the idea was conceived” or “Description of the idea” etc.., manual annotation is required that grades them into a single categorical variable based on the expert’s evaluation of the idea.
The manual annotation could also be automated using topics modeling that groups the free text into “topics” and later assigns words in the text to these topics with certain probabilities using LDT or K-means clustering or similar algorithms. And these topics themselves could be mapped to categorical variables.
The existing dataset should be mapped to these manual annotations. This is a one-time effort for existing dataset.
Once, the dataset is organized in a standard format, it could be used to train a kNN classifier.
After verifying the performance of the classifier, it could be integrated into the portal.
Any new idea submitted will have it’s output (Profitability index) automatically calculated and displayed in the screen to the ideator.
The real challenge in building and integrating a kNN classifier will be in: a) organizing existing data, b) mapping annotations (manual or automated) to categorical variables, and c) availability of reasonable amount of existing data for training.